Flash Attention is an important algorithmic rewrite of the attention operation. It is what allows transformers to scale to long sequence lengths. The idea is simple, but the implementations that exist can be complex, heavily optimised, and hard to parse.
I wanted to write the smallest possible implementation of Flash Attention in CUDA that is still correct and complete. nanoFlash is the result: the entire forward pass in ~30 lines of kernel code.
The Problem
In a transformer, each token in a sequence of length produces three vectors of dimension ,
a query (what this token wants to know), a key (what this token can be asked about), and a value (what this token actually says). Stacking these across all tokens gives three matrices: , , , each . Attention computes , which lets each token attend to every other token, weighted by the similarity of their queries and keys. The output is , the same shape as the inputs. The naive way to do this materialises the full attention matrix in GPU global memory. You need the entire matrix before you can apply softmax (which operates row-wise and needs the row max for numerical stability), and then multiply by . Memory is therefore in sequence length. For long sequences this is prohibitive, and the repeated reads & writes to global memory dominate runtime.
Flash Attention avoids this by never materialising the full attention matrix. Instead, it tiles the computation through shared memory (SRAM), processing small tiles of Q, K, and V at a time, and accumulating the output incrementally.
Online Softmax
The trick that makes this possible is online softmax. Standard softmax over a row of logits is:
This requires two passes: one to find (for numerical stability), one to exponentiate & sum. You need all the logits in memory at once.
Online softmax replaces this with a single-pass recurrence. It maintains a running max and a running sum , updated as each new element arrives:
When a new element produces a larger max, the term rescales the previously accumulated sum. After all elements are processed, is the correct softmax denominator. No second pass needed.
In Flash Attention, this recurrence operates on tiles rather than individual elements, which is what allows it to stream through K/V without ever needing all the logits in memory at once.
Tiling
The attention matrix is too large to materialise, but it can be computed in tiles. Q is divided into tiles of rows each. K and V are divided into tiles of rows each. One tile of Q and one tile of K together produce a sub-tile of the attention matrix, which fits in SRAM.
The outer loop iterates over tiles of K and V (), loading one tile at a time from HBM into SRAM. The inner loop iterates over tiles of Q (), loading each into SRAM against the current K/V tile. Each (Q, K, V) tile triple computes a sub-tile of attention on-chip, and the output is accumulated back to HBM.
The diagram below (from the original paper) shows this data flow.
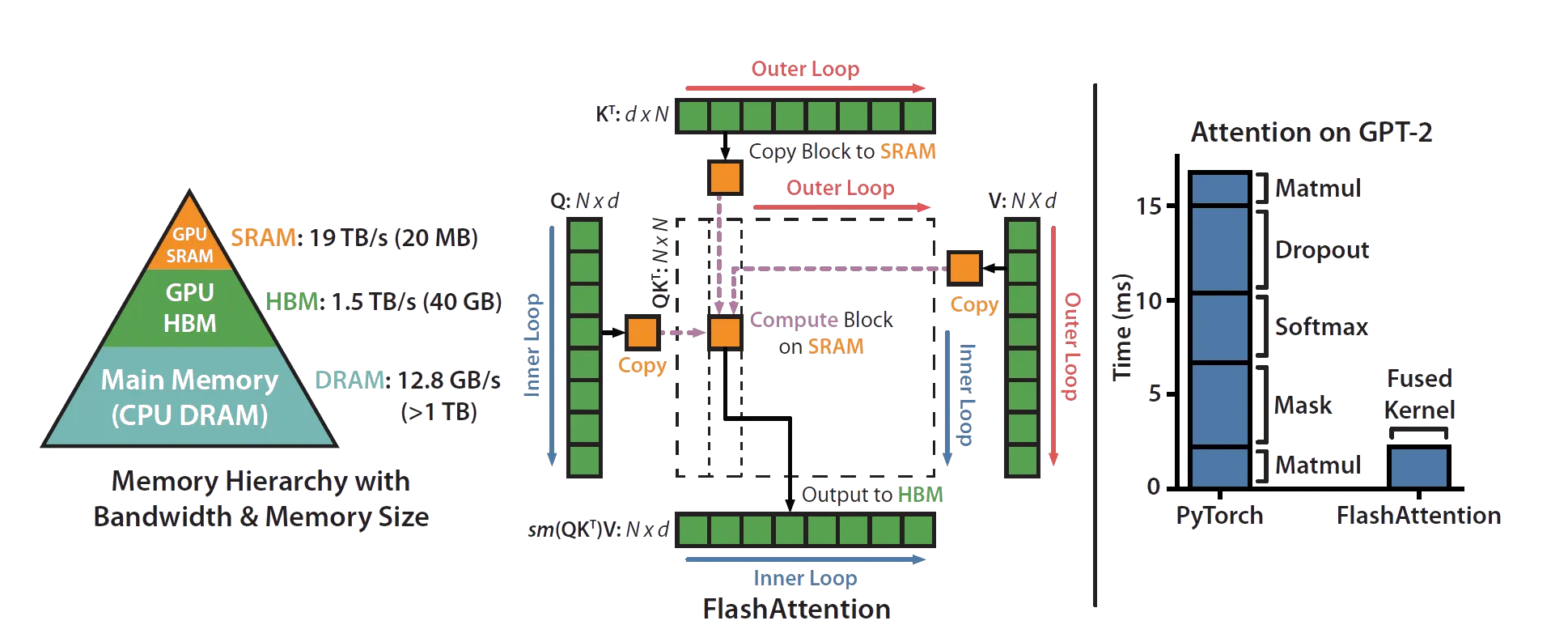
For each pair of tiles:
- Load tile and into SRAM
- For each Q tile, compute local attention scores
- Run online softmax on (update running max & sum)
- Accumulate the weighted output , rescaled by the running statistics
K and V are loaded once per outer iteration and reused across all Q tiles. This is where the memory savings come from: instead of reading K and V times, you read them times.
The tile size itself is determined by how much SRAM the GPU has. nanoFlash computes this dynamically:
Three tiles (Q, K, V) of size plus the score matrix need to fit simultaneously.
The Kernel
The entire implementation is one file, cuda.cu. The kernel is ~30 lines. Here is what each part does.
Setup. The kernel receives dynamically allocated shared memory and partitions it into four regions: Qi, Kj, Vj (the three tile buffers) and S (the score matrix). Each thread handles one row of a tile. The grid is (batch_size, num_heads), so each block processes one (batch, head) pair independently.
Loading K/V. The outer loop iterates over column tiles. Each thread loads one row of K and one row of V from global memory into shared memory. A __syncthreads() ensures the entire tile is loaded before any thread starts computing with it.
Computing Scores. The inner loop iterates over Q row tiles. Each thread loads its row of Q, then computes the dot product of that row against every row of the K tile: . It tracks the row maximum as it goes.
Online Softmax. Two lines do the softmax. First, shift each logit by the row max and exponentiate: , accumulating the row sum. Then merge with the running statistics from previous tiles:
and are the running max and sum across all column tiles seen so far. The terms rescale the old statistics when a new tile produces a larger maximum. This is the core of the numerical stability guarantee.
Output Accumulation. This is the most subtle line. For each output element, the kernel computes (the attention-weighted value for this tile), then updates the output:
The old output is rescaled by how much the running max changed, and the new contribution is added with its own scaling. After all column tiles are processed, the running statistics converge to the true softmax denominator, and the output is exact.
Launch. The forward() function queries the GPU's shared memory capacity, computes tile sizes (), allocates the running statistics ( initialised to 0, to ), and launches the kernel.
There is no backward pass, no mixed precision, no causal masking, no multi-GPU support.
Just the core algorithm, as clearly as I could write it.